内存¶
什么是内存?¶
内存是一种认知功能,它使人们能够存储、检索和使用信息来理解他们的现在和未来。想想看,与一个总是忘记你告诉他们的事情、需要不断重复的同事共事是多么令人沮丧!随着AI代理承担涉及大量用户交互的更复杂任务,为它们配备内存对于效率和用户满意度同样至关重要。通过内存,代理可以从反馈中学习并适应用户的偏好。本指南涵盖了基于召回范围的两种内存类型
短期记忆,或线程范围的记忆,可以随时从单个用户对话线程中召回。LangGraph将短期记忆作为代理状态的一部分进行管理。状态通过检查点持久化到数据库中,以便线程可以随时恢复。短期记忆在图被调用或步骤完成时更新,并在每个步骤开始时读取状态。
长期记忆在对话线程之间共享。它可以在任何时候和任何线程中召回。记忆可以限定在任何自定义命名空间,而不仅仅是单个线程ID。LangGraph提供存储(参考文档)来让你保存和召回长期记忆。
这两种记忆对于你的应用程序都非常重要,需要理解并实现。
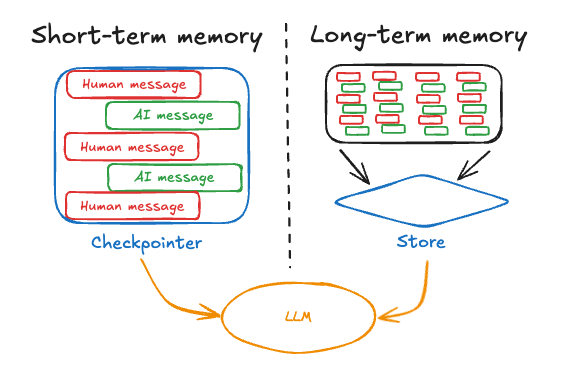
短期记忆¶
短期记忆允许你的应用程序记住单个线程或对话中的先前交互。线程在一个会话中组织多个交互,类似于电子邮件将消息分组到单个对话中的方式。
LangGraph将短期记忆作为代理状态的一部分进行管理,通过线程范围的检查点持久化。这种状态通常可以包括对话历史以及其他有状态数据,例如上传的文件、检索到的文档或生成的工件。通过将这些存储在图的状态中,机器人可以访问给定对话的完整上下文,同时保持不同线程之间的分离。
由于对话历史是表示短期记忆最常见的形式,在下一节中,我们将介绍在消息列表变得很长时管理对话历史的技术。如果你想坚持高层概念,请继续阅读长期记忆部分。
管理长对话历史记录¶
长对话对当今的LLM构成了挑战。完整的历史记录甚至可能无法完全放入LLM的上下文窗口中,导致不可恢复的错误。即使你的LLM技术上支持完整的上下文长度,大多数LLM在长上下文下表现仍然不佳。它们会被过时或偏离主题的内容“分散注意力”,同时响应时间变慢,成本也更高。
管理短期记忆是平衡精确度与召回率与应用程序其他性能要求(延迟和成本)之间的练习。一如既往,批判性地思考如何为你的LLM表示信息并查看你的数据非常重要。我们将在下面介绍一些管理消息列表的常用技术,并希望为你提供足够的上下文,以便你为应用程序选择最佳的权衡方案
编辑消息列表¶
聊天模型使用消息接受上下文,其中包括开发者提供的指令(系统消息)和用户输入(人类消息)。在聊天应用程序中,消息在人类输入和模型响应之间交替,导致消息列表随时间增长。由于上下文窗口有限,并且包含大量token的消息列表可能成本高昂,许多应用程序可以通过使用手动删除或忘记过时信息的技术而受益。
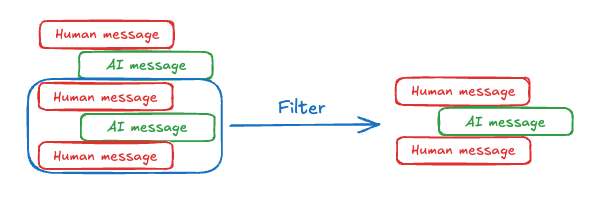
最直接的方法是从列表中删除旧消息(类似于最近最少使用缓存)。
在LangGraph中,从列表中删除内容的典型技术是从节点返回一个更新,告诉系统删除列表的某些部分。你可以定义这种更新的样式,但一种常见的方法是让你返回一个对象或字典,指定要保留哪些值。
def manage_list(existing: list, updates: Union[list, dict]):
if isinstance(updates, list):
# Normal case, add to the history
return existing + updates
elif isinstance(updates, dict) and updates["type"] == "keep":
# You get to decide what this looks like.
# For example, you could simplify and just accept a string "DELETE"
# and clear the entire list.
return existing[updates["from"]:updates["to"]]
# etc. We define how to interpret updates
class State(TypedDict):
my_list: Annotated[list, manage_list]
def my_node(state: State):
return {
# We return an update for the field "my_list" saying to
# keep only values from index -5 to the end (deleting the rest)
"my_list": {"type": "keep", "from": -5, "to": None}
}
只要在"my_list"键下返回更新,LangGraph就会调用manage_list "reducer"函数。在该函数中,我们定义接受哪些类型的更新。通常,消息会被添加到现有列表中(对话会增长);但是,我们也添加了对接受字典的支持,该字典允许你"保留"状态的某些部分。这允许你通过编程方式删除旧的消息上下文。
另一种常见的方法是让你返回一个“移除”对象的列表,该列表指定要删除的所有消息的ID。如果你在LangGraph中使用LangChain消息和add_messages reducer(或MessagesState,它使用相同的基础功能),你可以使用RemoveMessage来完成此操作。
API参考:RemoveMessage | AIMessage | add_messages
from langchain_core.messages import RemoveMessage, AIMessage
from langgraph.graph import add_messages
# ... other imports
class State(TypedDict):
# add_messages will default to upserting messages by ID to the existing list
# if a RemoveMessage is returned, it will delete the message in the list by ID
messages: Annotated[list, add_messages]
def my_node_1(state: State):
# Add an AI message to the `messages` list in the state
return {"messages": [AIMessage(content="Hi")]}
def my_node_2(state: State):
# Delete all but the last 2 messages from the `messages` list in the state
delete_messages = [RemoveMessage(id=m.id) for m in state['messages'][:-2]]
return {"messages": delete_messages}
在上面的示例中,add_messages reducer允许我们将新消息追加到messages状态键,如my_node_1中所示。当它看到一个RemoveMessage时,它将从列表中删除该ID的消息(然后RemoveMessage将被丢弃)。有关LangChain特定消息处理的更多信息,请查看此关于使用RemoveMessage的操作指南。
有关示例用法,请参阅此操作指南以及我们LangChain Academy课程的模块2。
总结过往对话¶
如上所示,修剪或移除消息的问题在于,我们可能会因为消息队列的淘汰而丢失信息。因此,一些应用程序受益于使用聊天模型总结消息历史的更复杂方法。
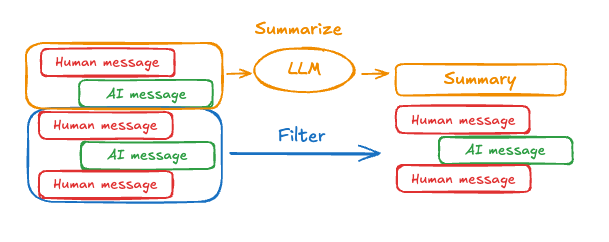
可以使用简单的提示和编排逻辑来实现此目的。例如,在LangGraph中,我们可以扩展MessagesState以包含一个summary键。
然后,我们可以生成聊天历史的摘要,使用任何现有摘要作为下一个摘要的上下文。这个summarize_conversation节点可以在messages状态键中积累一定数量的消息后被调用。
def summarize_conversation(state: State):
# First, we get any existing summary
summary = state.get("summary", "")
# Create our summarization prompt
if summary:
# A summary already exists
summary_message = (
f"This is a summary of the conversation to date: {summary}\n\n"
"Extend the summary by taking into account the new messages above:"
)
else:
summary_message = "Create a summary of the conversation above:"
# Add prompt to our history
messages = state["messages"] + [HumanMessage(content=summary_message)]
response = model.invoke(messages)
# Delete all but the 2 most recent messages
delete_messages = [RemoveMessage(id=m.id) for m in state["messages"][:-2]]
return {"summary": response.content, "messages": delete_messages}
有关示例用法,请参阅此处的此操作指南,以及我们LangChain Academy课程的模块2。
知道何时移除消息¶
大多数LLM都有一个最大支持的上下文窗口(以token计)。一个决定何时截断消息的简单方法是计算消息历史中的token数量,并在接近该限制时进行截断。简单的截断很容易自行实现,尽管有一些“陷阱”。一些模型API进一步限制了消息类型的顺序(必须以人类消息开始,不能有连续的相同类型的消息等)。如果你正在使用LangChain,你可以使用trim_messages实用程序,并指定要从列表中保留的token数量,以及用于处理边界的strategy(例如,保留最后max_tokens)。
下面是一个例子。
API参考:trim_messages
from langchain_core.messages import trim_messages
trim_messages(
messages,
# Keep the last <= n_count tokens of the messages.
strategy="last",
# Remember to adjust based on your model
# or else pass a custom token_encoder
token_counter=ChatOpenAI(model="gpt-4"),
# Remember to adjust based on the desired conversation
# length
max_tokens=45,
# Most chat models expect that chat history starts with either:
# (1) a HumanMessage or
# (2) a SystemMessage followed by a HumanMessage
start_on="human",
# Most chat models expect that chat history ends with either:
# (1) a HumanMessage or
# (2) a ToolMessage
end_on=("human", "tool"),
# Usually, we want to keep the SystemMessage
# if it's present in the original history.
# The SystemMessage has special instructions for the model.
include_system=True,
)
长期记忆¶
LangGraph中的长期记忆允许系统在不同的对话或会话中保留信息。与线程范围的短期记忆不同,长期记忆保存在自定义的“命名空间”中。
存储记忆¶
LangGraph将长期记忆作为JSON文档存储在存储中(参考文档)。每个记忆都组织在一个自定义的namespace(类似于文件夹)和一个独特的key(像文件名)之下。命名空间通常包括用户或组织ID或其他标签,以便于组织信息。这种结构实现了记忆的层次化组织。通过内容过滤器支持跨命名空间搜索。请参阅下面的示例。
from langgraph.store.memory import InMemoryStore
def embed(texts: list[str]) -> list[list[float]]:
# Replace with an actual embedding function or LangChain embeddings object
return [[1.0, 2.0] * len(texts)]
# InMemoryStore saves data to an in-memory dictionary. Use a DB-backed store in production use.
store = InMemoryStore(index={"embed": embed, "dims": 2})
user_id = "my-user"
application_context = "chitchat"
namespace = (user_id, application_context)
store.put(
namespace,
"a-memory",
{
"rules": [
"User likes short, direct language",
"User only speaks English & python",
],
"my-key": "my-value",
},
)
# get the "memory" by ID
item = store.get(namespace, "a-memory")
# search for "memories" within this namespace, filtering on content equivalence, sorted by vector similarity
items = store.search(
namespace, filter={"my-key": "my-value"}, query="language preferences"
)
长期记忆的思考框架¶
长期记忆是一个复杂的挑战,没有一劳永逸的解决方案。然而,以下问题提供了一个结构化框架,帮助你探索不同的技术
记忆的类型是什么?
人类利用记忆来记住事实、经验和规则。AI代理也可以以相同的方式使用记忆。例如,AI代理可以使用记忆来记住关于用户的具体事实以完成任务。我们将在下面的部分中详细介绍几种记忆类型。
你希望何时更新记忆?
记忆可以作为代理应用程序逻辑的一部分进行更新(例如,“在热路径上”)。在这种情况下,代理通常在响应用户之前决定记住事实。或者,记忆可以作为后台任务进行更新(在后台/异步运行并生成记忆的逻辑)。我们将在下面的部分中解释这些方法之间的权衡。
记忆类型¶
不同的应用程序需要各种类型的记忆。尽管类比并不完美,但研究人类记忆类型可以提供深刻的见解。一些研究(例如,CoALA论文)甚至将这些人类记忆类型映射到了AI代理中使用的类型。
| 记忆类型 | 存储内容 | 人类示例 | 代理示例 |
|---|---|---|---|
| 语义 | 事实 | 我在学校学到的东西 | 关于用户的事实 |
| 情景 | 经验 | 我做过的事情 | 代理过去的行动 |
| 程序 | 指令 | 本能或运动技能 | 代理系统提示 |
语义记忆¶
语义记忆,无论是对人类还是AI代理,都涉及特定事实和概念的保留。在人类中,它可能包括在学校学到的信息以及对概念及其关系的理解。对于AI代理,语义记忆通常用于通过记住过去交互中的事实或概念来个性化应用程序。
注意:不要与“语义搜索”混淆,后者是使用“意义”(通常作为嵌入)查找相似内容的技术。语义记忆是心理学中的一个术语,指的是存储事实和知识,而语义搜索是根据意义而非精确匹配检索信息的方法。
个人资料¶
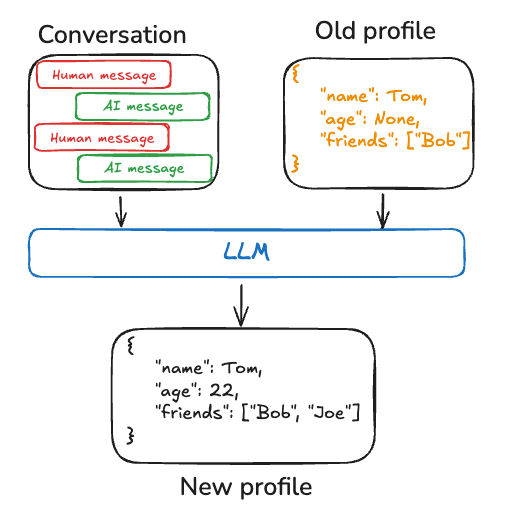
语义记忆可以通过不同方式进行管理。例如,记忆可以是一个单一的、持续更新的“配置文件”,其中包含关于用户、组织或其他实体(包括代理本身)的范围明确且具体的信息。配置文件通常只是一个JSON文档,包含你为表示你的领域而选择的各种键值对。
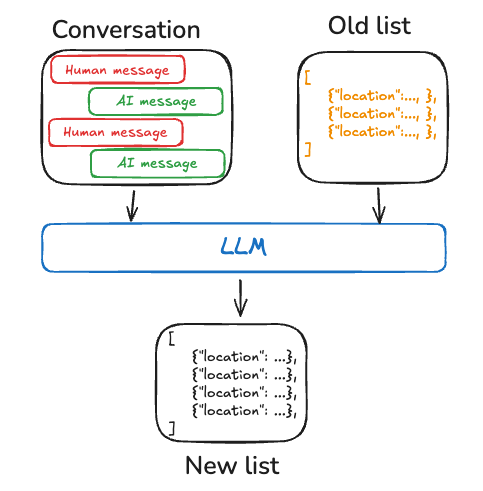
在记忆配置文件时,你会希望确保每次都更新配置文件。因此,你会希望传入先前的配置文件并要求模型生成新的配置文件(或应用于旧配置文件的某些JSON补丁)。随着配置文件变大,这可能会变得容易出错,并且可能受益于将配置文件拆分为多个文档或生成文档时进行严格解码,以确保记忆模式保持有效。
集合¶
或者,记忆可以是一个文档集合,随着时间的推移不断更新和扩展。每个单独的记忆可以更狭窄地限定范围,更容易生成,这意味着你随着时间的推移丢失信息的可能性更小。LLM更容易为新信息生成新对象,而不是将新信息与现有配置文件进行协调。因此,文档集合往往会带来更高的下游召回率。
然而,这会增加内存更新的复杂性。模型现在必须删除或更新列表中的现有项目,这可能很棘手。此外,某些模型可能默认过度插入,而另一些模型可能默认过度更新。请参阅Trustcall包以了解一种管理此问题的方法,并考虑使用评估工具(例如,使用LangSmith)来帮助你调整行为。
处理文档集合也将复杂性转移到了列表的内存搜索上。Store目前支持语义搜索和按内容过滤。
最后,使用记忆集合可能会给模型提供全面的上下文带来挑战。尽管单个记忆可能遵循特定的模式,但这种结构可能无法捕捉记忆之间的完整上下文或关系。因此,在使用这些记忆生成响应时,模型可能缺乏在统一配置文件方法中更容易获得的重要上下文信息。
无论记忆管理方法如何,核心点是代理将使用语义记忆来支撑其响应,这通常会带来更个性化和相关的交互。
情景记忆¶
情景记忆,无论是对人类还是AI代理,都涉及回忆过去的事件或行动。CoALA论文对此作了很好的阐述:事实可以写入语义记忆,而经验可以写入情景记忆。对于AI代理,情景记忆通常用于帮助代理记住如何完成任务。
在实践中,情景记忆通常通过少样本提示来实现,代理通过过去的序列学习来正确执行任务。有时“展示”比“告知”更容易,LLM从示例中学习得很好。少样本学习让你通过用输入-输出示例更新提示来“编程”你的LLM,以说明预期的行为。虽然可以使用各种最佳实践来生成少样本示例,但挑战通常在于根据用户输入选择最相关的示例。
请注意,记忆存储只是将数据存储为少样本示例的一种方式。如果你想让开发者有更多参与,或者将少样本更紧密地与你的评估工具联系起来,你还可以使用LangSmith数据集来存储你的数据。然后,动态少样本示例选择器可以开箱即用地实现此目标。LangSmith会为你索引数据集,并能够根据关键词相似性(使用类似BM25的算法进行关键词相似性)检索与用户输入最相关的少样本示例。
有关LangSmith中动态少样本示例选择的示例用法,请参阅此操作视频。此外,请参阅这篇博客文章,展示了如何使用少样本提示来提高工具调用性能,以及这篇博客文章,如何使用少样本示例使LLM与人类偏好保持一致。
程序记忆¶
程序记忆,无论是对人类还是AI代理,都涉及记住执行任务所用的规则。在人类中,程序记忆就像内化的执行任务的知识,例如通过基本运动技能和平衡来骑自行车。另一方面,情景记忆涉及回忆特定经历,例如第一次成功不带辅助轮骑自行车,或者一次难忘的风景优美的自行车之旅。对于AI代理,程序记忆是模型权重、代理代码和代理提示的组合,它们共同决定了代理的功能。
在实践中,代理修改其模型权重或重写其代码是相当不常见的。然而,代理修改自己的提示则更为常见。
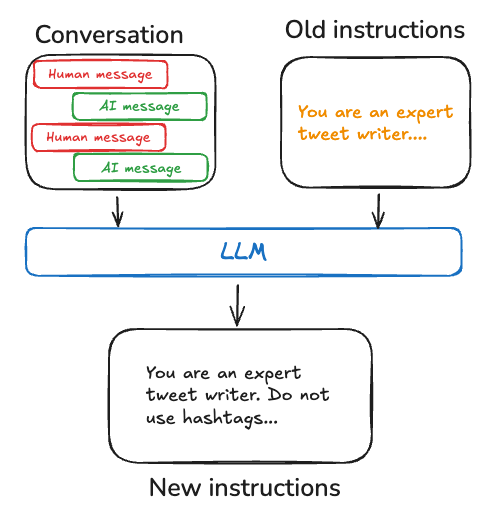
完善代理指令的一种有效方法是通过“反思”或元提示。这涉及用其当前指令(例如,系统提示)以及最近的对话或明确的用户反馈来提示代理。然后,代理根据这些输入完善自己的指令。这种方法对于难以预先指定指令的任务特别有用,因为它允许代理从其交互中学习和适应。
例如,我们构建了一个推文生成器,它使用外部反馈和提示重写来生成高质量的论文摘要,用于Twitter。在这种情况下,特定的摘要提示很难先验指定,但用户很容易批评生成的推文并提供如何改进摘要过程的反馈。
下面的伪代码展示了如何使用LangGraph内存存储实现这一点,使用存储来保存提示,update_instructions节点获取当前提示(以及从与用户对话中捕获的state["messages"]中的反馈),更新提示,并将新提示保存回存储。然后,call_model从存储中获取更新的提示并使用它来生成响应。
# Node that *uses* the instructions
def call_model(state: State, store: BaseStore):
namespace = ("agent_instructions", )
instructions = store.get(namespace, key="agent_a")[0]
# Application logic
prompt = prompt_template.format(instructions=instructions.value["instructions"])
...
# Node that updates instructions
def update_instructions(state: State, store: BaseStore):
namespace = ("instructions",)
current_instructions = store.search(namespace)[0]
# Memory logic
prompt = prompt_template.format(instructions=instructions.value["instructions"], conversation=state["messages"])
output = llm.invoke(prompt)
new_instructions = output['new_instructions']
store.put(("agent_instructions",), "agent_a", {"instructions": new_instructions})
...
写入记忆¶
虽然人类通常在睡眠期间形成长期记忆,但AI代理需要不同的方法。代理何时以及如何创建新记忆?代理至少有两种主要方法来写入记忆:“热路径上”和“后台中”。
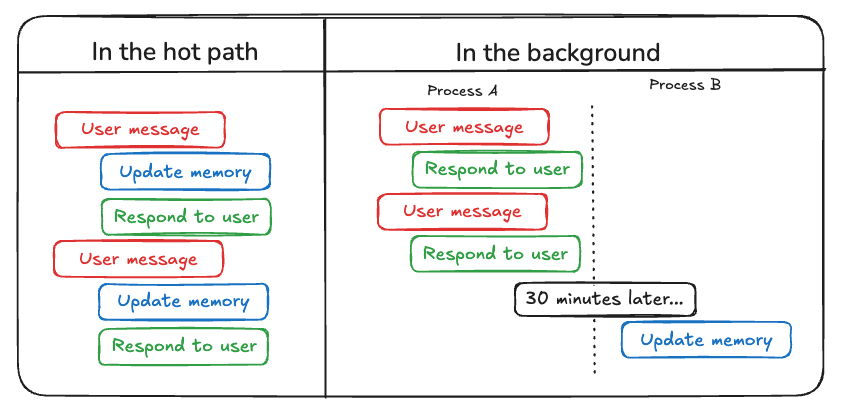
在热路径中写入记忆¶
在运行时创建记忆既有优点也有挑战。积极的一面是,这种方法允许实时更新,使新记忆立即可用于后续交互。它还实现了透明性,因为可以在创建和存储记忆时通知用户。
然而,这种方法也带来了挑战。如果代理需要一个新工具来决定提交什么内容到内存中,它可能会增加复杂性。此外,思考要保存到内存中的过程可能会影响代理的延迟。最后,代理必须在记忆创建和其其他职责之间进行多任务处理,这可能会影响所创建记忆的数量和质量。
例如,ChatGPT使用save_memories工具将记忆作为内容字符串进行插入更新,并根据每条用户消息决定是否以及如何使用此工具。请参阅我们的memory-agent模板作为参考实现。
在后台写入记忆¶
将记忆创建作为单独的后台任务具有多种优势。它消除了主应用程序中的延迟,将应用程序逻辑与内存管理分离,并允许代理更专注地完成任务。这种方法还提供了灵活的内存创建时间安排,以避免重复工作。
然而,这种方法也有其自身的挑战。确定记忆写入的频率变得至关重要,因为不频繁的更新可能会导致其他线程缺少新的上下文。决定何时触发记忆形成也很重要。常见的策略包括在设定的时间段后安排(如果发生新事件则重新安排)、使用cron调度,或允许用户或应用程序逻辑手动触发。
请参阅我们的memory-service模板作为参考实现。